
Solving Heterogeneous Programming Challenges with Fortran and OpenMP
Introduction
Heterogenous computing has stayed at the center stage of computer science for decades. Now, it has become more mission-critical and holds the key to business success, riding the wave of blooming hardware diversification, ripe solution of cloud computing, and exponential growth of AI/ML computation demands, which boosts the specific purpose of hardware design. State-of-the-art software engineering, essential programming, and code design are required to meet several traits to adapt to the new technology trends of heterogeneous computation.

We can easily name a few of the most standing out traits but by no means reach a full list.
- Able to run on different hardware, such as CPU, GPU, FPGA, and hardware from different vendors.
- Able to recognize and take advantage of different memory models, such as host and device memory, different types of memories on the device, and different memory images loaded by the hardware scheduler.
- Able to run in acyclic graph execution order,
- Able to program on existing APIs of other established libraries and interoperate with other backend kernels.
Kernal and Directive-Based Programming
In high-performance computing in the science, research, and engineering industry, the most important base languages for programming are C/C++ and Fortran. C/C++ is now the most popular choice, and Fortran is the oldest programming language, which still evolves vividly and carries a code base of monstrous size, mission-critical, and super sophisticated. Fortran-based language continuously evolves over time. Modern Fortran is a general-purpose, compiled imperative programming language especially suited to numeric computation and scientific computing.
The advancement of heterogenous computing is constantly reshaping the paradigm of the base languages. The two most successful and popular frameworks of heterogeneous computing for general programmers are kernel programming and directives-based programming.
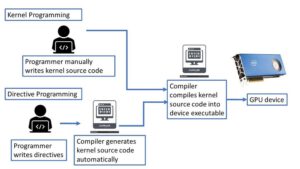
Kernel programming is usually implemented by base language extension. The programmers take most of the heavy lifting work to figure out how to arrange the computation on the target hardware. Some popular examples are CUDA, SYCL, and OpenCL for C/C++. We have another full paper talking about SYCL and other prescriptive parallelism programming. There is no mainstream kernel programming model for Fortran. Fortran programmers can interlanguage call C/C++ codes and consume the CUDA/SYCL/OpenCL kernels running on the GPUs.
The other important framework is directive programming. Compared to coding on hardware-specified language extensions to generate hardware-targeted code kernels, directive programming emphasizes the “single code body” trait. Under the directives programming assumption, there is only one set of source code, which will run on multiple platforms with/without different types of accelerators. The code should be simply treated as the original code if the compiler does not understand the directives or chooses to turn off the directive treatment of the code. The two most popular directives-based programming standards are OpenACC and OpenMP. Although with a shorter history compared to OpenMP, OpenACC, developed by Cray, CAPS, Nvidia, and PGI, obtains the recognition of the world’s 1st high-level directives-based programming model for high-performance computing for CPUs, GPUs, and a variety of accelerators.
Challenge
Directive programming targets domain scientists as the primary audience, many of whom have learned only enough computer programming to express their algorithms in code. Frequently, these developers do not have the programming background and/or time required to explicitly parallelize their algorithms using a kernel programming model, such as CUDA/SYCL/OpenCL. As developers, domain scientists can easily adapt to the descriptive style to express the parallelism in the code, such as the loop structure is eligible for concurrent; the matrix is only used as input but does not need to be transferred for output; some function calls could be called on device only. OpenMP enables these users to maintain the familiar coding style of loops and arrays while still accelerating the code through modern GPUs by simplifying data management to eliminate the need for device and host arrays and transforming loops automatically into GPU kernels. Also, existing code variants can be dispatched to available accelerator devices. OpenMP is often simpler for new users and domain scientists to learn. Meanwhile, the developer tools vendor can work hand in hand to develop the compiler to consume more and more complicated directives to exert the best potential of the accelerators.
Solution
How Fortran+OpenMP offload works in heterogeneous computing
Next, we will explain, by examples, how Fortran+OpenMP offloading solves the heterogenous computing challenges in three main aspects we discussed above:
- offloading.
- memory management.
- calling existing APIs on device. We assume you have basic knowledge of Fortran and OpenMP. The code snippets here are not the full code for compiling, and the variable declaration/initialization is omitted to keep the paragraph concise. The full version of the code examples can be found in the OpenMP official reference document(https://www.openmp.org/wp-content/uploads/openmp-examples-5.1.pdf).
Deep Dive into the Solution
Offloading
We start with the first set of examples showing offloading to GPU.
The first example takes data movement into account. The target construct offloads a code region to a target device. The variables p, v1, and v2 are explicitly mapped to the target device using the map clause. The variable N is implicitly mapped to the target device.
!$omp target map(v1,v2,p) !$omp parallel do do i=1,N p(i) = v1(i) * v2(i) end do !$omp end target
This is the simple scaler data movement. The pointer, structure(aggregate), allocatable array, and mapping mechanism are more advanced topics not in the scope here.
The second example shows how the target teams and the distribute parallel do constructs are used to execute a loop in a target teams region. The target teams construct creates a league of teams where the primary thread of each team executes the teams region.
Each primary thread executing the team’s region has a private copy of the variable sum created by the reduction clause on the team’s construct. The primary thread and all threads in its team have a private copy of the variable sum created by the reduction clause on the parallel loop construct. The second private sum is reduced into the primary thread’s private copy of the sum created by the team’s construct. At the end of the team’s region, each primary thread’s private copy of the sum is reduced into the final sum implicitly mapped into the target region.
The number of teams in the league is less than or equal to the variable num_blocks. Each team in the league has several threads less than or equal to the variable block_threads. The iterations in the outer loop are distributed among the primary threads of each team. When a team’s primary thread encounters the parallel loop construct before the inner loop, the other threads in its team are activated. The team executes the parallel region and then workshares the execution of the loop.
!$omp target map(to: B, C) map(tofrom: sum) !$omp teams num_teams(num_teams) thread_limit(block_threads) reduction(+:sum) !$omp distribute do i0=1,N, block_size !$omp parallel do reduction(+:sum) do i = i0, min(i0+block_size,N) sum = sum + B(i) * C(i) end do end do !$omp end teams !$omp end target
Memory Management
Now, we show an example of how OpenMP manages memory in a heterogeneous system.
The target data construct maps arrays v1 and v2 in the into a device data environment. The task executing on the host device encounters the first target region and waits for the completion of the region. After the execution of the first target region, the task executing on the host device then assigns new values to v1 and v2 in the task’s data environment by calling the function init_again_on_host(). The target update construct assigns the new values of v1 and v2 from the task’s data environment to the corresponding mapped array sections in the device data environment of the target data construct before executing the second target region.
!$omp target data map(to: v1, v2) map(from: p) !$omp target !$omp parallel do do i=1,N p(i) = v1(i) * v2(i) end do !$omp end target call init_again_on_host(v1, v2, N) !$omp target update to(v1, v2) !$omp target !$omp parallel do do i=1,N p(i) = p(i) + v1(i) * v2(i) end do !$omp end target !$omp end target data
Calling Existing APIs on Device.
The following example is an Intel extension implementation. Currently, it is only available on Intel compiler, ifx. The construct of extension is “target variant dispatch”. This directive causes the compiler to emit conditional dispatch code around the associated subroutine or function call that follows the directive. If the default device is available, the variant version is called. The following example shows how to use the “target variant dispatch” construct to call the MKL dgemm target device variant.
include “mkl_omp_offload.f90” program main use mkl_blas_omp_offload integer :: m = 10, n = 6, k = 8, lda = 12, ldb = 8, ldc = 10 integer :: sizea = lda * k, sizeb = ldb * n, sizec = ldc * n double :: alpha = 1.0, beta = 0.0 double, allocatable :: A(:), B(:), C(:) allocate(A(sizea)) ! Allocate matrices… … ! Initialize matrices… … !$omp target data map(to:A(1:sizea), B(1:sizeb)) map(tofrom:C(1:sizec)) !$omp target variant dispatch use_device_ptr(A, B, C) call dgemm(‘N’, ‘N’, m, n, k, alpha, A, lda, B, ldb, beta, C, ldc) ! Compute C = A * B on GPU !$omp end target variant dispatch !$omp end target data
OpenMP Implementations
OpenMP concentrates many community efforts as one of the few most popular directives programming frameworks. The new specification is published at a strong pace with substantial improvements and is full of new ideas.
AOMP is AMD’s LLVM/Clang based compiler that supports OpenMP and offloading to multiple GPU acceleration targets (multi-target). Intel® Fortran Compiler (ifx) is production-ready for CPUs and GPUs. The ifx compiler is based on the Intel® Fortran Compiler Classic (ifort) frontend and runtime libraries but uses LLVM backend compiler technology. NVIDIA HPC Compilers enable OpenMP for multicore CPUs on all platforms and target offload to NVIDIA GPUs. Other vendors, such as ARM, Flang, GNU, HPE, IBM, LLVM, Microsoft, and Oracle, actively provide robust implementations in their compiler products.
IFX
The Intel ifx compiler is the latest Intel product providing the heterogenous computing implementation for the Fortran community. The Intel Fortran Compiler (ifx) is a new compiler based on the Intel Fortran Compiler Classic (ifort) front-end and runtime libraries, using LLVM back-end technology. Currently, ifx supports features of the Fortran 95 language, OpenMP* 5.0 Version TR4, and some OpenMP Version 5.1 directives and offloading features. ifx is binary (.o/.obj) and module (.mod) file compatible; binaries and libraries generated with ifort can be linked with binaries and libraries built with ifx, and .mod files generated with one compiler can be used by the other. Both compilers use the ifort runtime libraries. ifx also supports GPU offloading. The compiler uses the latest standards, including Fortran 2003, Fortran 2018, and OpenMP 5.0 and 5.1 for GPU offload. Refer to the Conformance, Compatibility, and FortranFeatures for more information.
Opensource, base language evolution, multivendor
Fortran, as a base language, is by no means in the obsolete stage; by contrast, Fortran’s development is vivid and substantial. Facing a computing hardware and software blooming era, Fortran lives strong and stays mission-critical among numerous scientific and engineering projects. The robust implementations of OpenMP runtimes libraries provide descriptive ways to exploit parallelism and concurrency on target devices.
Learn more
For anyone who wants to learn more, nothing is better than going to your computer and trying it out yourself. The best collection of learning information about Intel implementation of Fortran+OpenMP offload are:
- Intel® Fortran Compiler Classic and Intel® Fortran Compiler Developer Guide and Reference
- OpenMP5.2 standards specification
The following webpage explains how to access Intel Developer Cloud (a free online account with access to Intel CPUs, GPUs, and FPGAs) and gives tutorials on trying the new Intel Fortran compiler ifx and OpenMP offload to GPU
https://www.intel.com/content/www/us/en/developer/tools/devcloud/overview.html
Following those directions, you can try out your first Fortran+OpenMP offload program a few minutes from now.