
Declarative Data Collection for Portable Parallel Performance using Intel® Toolkits
Introduction
Zhibo Li is a Research Assistant at the School of Informatics, University of Edinburgh, working with Prof. Björn Franke. Before that, he was a Computer Science Ph.D. student at the same institution, working on a project titled “Declarative Data Collections for Portable Performance based on oneAPI.” This project introduces a high-performance declarative data collection based on oneAPI, where the programmer declares a data collection only with the properties, and high-performance code will be auto-generated for multiple platforms such as Intel® Xeon Scalable Processors and Intel® Data Center GPUs.
Experience as A Student Ambassador
Zhibo was excited to join the student ambassador program and has had the opportunity to communicate with several other ambassadors and Intel engineers to learn and enhance his programming techniques and insights for cutting-edge products by Intel. Like other student ambassadors, he has been granted access to the Intel® Developer Cloud, enabling him to deploy his prototype library and benchmark on Intel’s most recent hardware, which greatly benefits his projects and his Ph.D. thesis.
As a student ambassador, he helped advocate the Intel Educator program to the director of teaching at his university, which helped develop his communication skills. Besides that, he presented at the oneAPI DevSummit 2023 and introduced his project to the audience worldwide, promoting his research and potential applications in broader areas. Also, he has been actively promoting oneAPI to diverse audiences through social media and conferences attended (Berlin Buzzwords 2023).
The Problem
Programmers find it difficult to write parallel programs; therefore, they tend to over-specify data structures and have sub-optimal issues with data containers.
The Solution
This project proposes Collection Skeletons – the abstractions for data collections that allow programmers to declare a data collection by requesting the properties they want without implementational details of the concrete data structures. This project has exposed semantic properties and interface properties from commonly used data structure libraries and Abstract Data Types (ADTs). With the property-based specification from the programmers, Collection Skeletons then decide on the concrete data structure and generate code for implicit parallelism based on oneTBB’s concurrent containers and oneDPL’s parallel algorithms. The programmer can also develop programs with algorithmic skeletons provided by Collection Skeletons as explicit parallelism, implemented based on oneAPI (SYCL) and oneDPL, for improved performance. Furthermore, they can also compile their programs with the SYCL enabled Intel® oneAPI DPC++/C++ Compiler as Collection Skeletons are modern C++ and compatible with DPC++.
Overview of Collection Skeletons
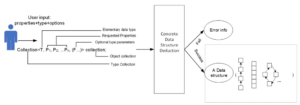
1. Overall working process
To help the programmers write efficient parallel code, this project proposes Collection Skeletons, where the programmers declare a data collection by requesting the properties they want; then, the deduction module will decide the concrete data structure – if the properties declaration is valid, the corresponding code will be generated. The decision-generating process is transparent to the programmers.
The opportunities for parallelism exist at the concrete data structure decision – when eligible, concurrent data structures such as concurrent_vector from oneTBB can be picked and generated; similarly, when eligible, parallelized member functions can be generated and performed over the concurrent containers. Figure 1 presents the overview process of interacting with Collection Skeletons.
2. API
Figure 2 presents the programming API from the programmer’s side – the API is implemented with C++ metaprogramming and accepts template parameters to facilitate the property-based declaration on a data collection.
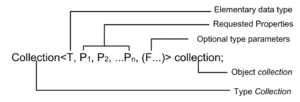
For example, a programmer would like a Sequential-accessible data collection of integers:
Collection<int, Seq> c;
From the view of the programmers, the template class and the declaration are only a notion; however, the library will perform much work in the background.
3. The concurrent/parallel backend (oneTBB + parallelized member functions)
Backends are implemented through oneTBB by wrapping containers from oneTBB and providing parallel versions for common algorithms such as find and sort.
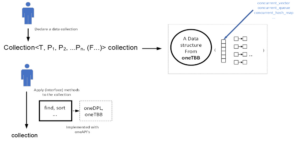
Considering the example below,
Collection<double, Rnd> c1;
//...initialisation of c1
double t = 0.1;
auto result = c1.find(t)The programmer requests a data collection of randomly accessible data to store double data. Then, they would like to find if c1 contains a 0.1.
With the implicit parallelism, for the decision of the concrete data structure and the associated member functions, c1 will be a concurrent vector and find will be generated as a multi-threaded version.
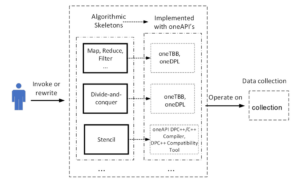
4. Explicit parallelism – Algorithmic Skeletons
We have implemented simple data-centric algorithmic skeletons, including map, reduce, filter, zip, scan, and complex data-centric algorithmic skeleton stencil. As Collection Skeletons are designed to be flexible to enclose more concrete data structures as well as algorithmic skeletons, there can also be multiple versions of one skeleton. For example, a map can be implemented through parallel_for from oneTBB or transform from oneDPL (which can even have more backends itself). Figure 4 shows the overview of the implementation for explicit parallelism.
5. Evaluation and Results
We evaluated our Collection Skeletons library against 17 benchmark suites, including Olden and other open-source projects. For this evaluation, we manually rewrote the legacy benchmarks written in C but replaced the low-level user-defined data structures and their access functions with their equivalent property-based collections from our Collection Skeletons library. The rewritten benchmarks were compiled with Clang++12. We executed the original programs to measure their computational time, serving as the baseline for speedup calculations.
Figure 5 presents the sequential computational performance variation (speedup) across the 17 benchmarks. A speedup greater than 1 indicates a performance increase compared to the original benchmark, while a value less than 1 suggests a performance decline. Most of the replaced benchmarks have similar or better computational performance than the baseline.
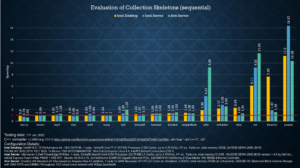
We ported the rewritten code to parallel execution by enabling concurrent containers from oneTBB as the backend and introducing parallel algorithmic skeletons developed based on oneDPL and SYCL. Note that there is no need to modify the source code of the rewritten code; only minor modifications to the build configurations are applied.
Although most of the benchmarks can be parallelized, only a few report performance boosts compared to the serial ones. Figure 6 presents the benchmarks that achieve performance boosts through parallelization and their speedup.
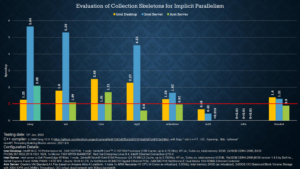
The rewritten benchmarks can also be compiled with the Intel oneAPI DPC++/C++ Compiler (i.e., the “clang++” compiler driver can be replaced with “icpx”) as the source code is modern C++ and fully compatible with SYCL-enabled DPC++.
Use Case
Program Jacobi-1d and Jacobi-2d with Collection Skeletons[1]
Jacobi-1d and Jacobi-2d rewritten with (sequential) Collection Skeletons vs Jacobi-1d and Jacobi-2d rewritten with SYCL-enabled Collection Skeletons (enabled with Algorithmic Skeletons based on oneAPI)
Jacobi 1d and Jacobi 2d benchmarks
As defined in Wikipedia, Stencil computations are a class of numerical data processing solution which update array elements according to some fixed pattern,
[1] Original sources available at https://github.com/MatthiasJReisinger/PolyBenchC-4.2.1
called a stencil. [2] Jacobi-1d and Jacobi-2d are common stencil patterns. Both original benchmarks are written in C programming language for the tested benchmark programs and can only perform on a CPU in sequential mode. Porting them to parallel platforms to enhance their computational performance is reasonable. However, under traditional methods, major rewriting of the original source code is required. For example, if a programmer wants to port the original code to a CUDA platform, they need to rewrite the computation into a CUDA kernel; moreover, the data structure and data (memory) management need to be redesigned for CUDA device and host.

[2] https://en.wikipedia.org/wiki/Stencil

If the programmers want to port it to another parallel platform, they need to do the rewrite again, which is tedious. Furthermore, the implementational details of the parallel platforms also hinder the programmer from developing a good parallel program.
However, with Collection Skeletons, they can conveniently develop parallel programs.
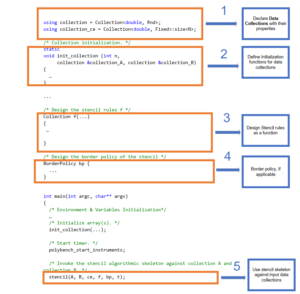
Firstly, Collection Skeletons introduce a stencil algorithmic skeleton that covers some common stencil kernels, including Jacobi-1d and Jacobi-2d,
template<typename Collection, typename CE, typename Func>
void stencil(Collection &collection_A, Collection &collection_B, CE ce, Func f, BorderPolicy bp, int t) {}This implementation works with the property-based Data Collections of Collection Skeletons, and it has both sequential and SYCL-based parallel version implementations. The Collection Skeletons library performs a compile-time properties check on whether a parallel stencil against Collections collection_A and collection_B is feasible. If yes, a SYCL-based parallel stencil will be generated; otherwise, a sequential stencil will be generated. In either case, the programmer only
needs to perform a few steps on rewriting/writing the program:
- Express the stencil rule with function f.
- Design the border policy as an object bp.
- Declare the Collections that store the data (input and output) with properties.
Collection<int, int, int> function(){
return Collection{-1, 0, 1};
}Where, for example, a Collection can be declared with properties and deducted as a std::tuple.
using collection = Collection<double, Rnd>;
using collection_ce = Collection<double, Fixed>:size<N>;Where collection is the type of collection_A and collection_B, which are input data for the stencil; collection_ce corresponds to ce, which stores the coefficients of the stencil kernel.
The rewritten code is now more concise, readable, and functional. Let us evaluate the performance.
Based on the above analysis, we evaluate the performance of our rewritten programs. We run the source code (written in legacy C) on an Intel Desktop. As Collection Skeletons provide both sequential and SYCL-parallel stencils, we test both implementations separately to compare the computational time.
- For Jacobi 1d, the input parameters are “N=400000, TSTEPS=10000”.
- For Jacobi 2d, the input parameters are “N=2800, TSTEPS=1000”.
- For SYCL-parallel stencil, the tested device is an Intel® Core™ i7-10710U CPU with “sycl:cpu_selector{}”. However, the SYCL-parallel stencil code can easily be ported to GPU-enabled platforms to enhance computation.
Figure 10 below presents the computational times for the three versions. As shown, the SYCL-parallel stencil offers better computational performance compared to both the original and the sequential versions provided by our Collection Skeletons.

Software & Hardware?
The software
- Intel® oneAPI, including SYCL, oneDPL, oneTBB, DPC++
The hardware
- Intel CPU and GPU experiments performed on Intel® Gold 6154 (Intel Server), Intel® Core™ i7-10710U, and Intel UHD Graphics (Intel Desktop), but can be applied to many Intel CPUs and GPUs. Limited compatibility with Arm* CPU (Arm Server).
More Resources
- SLE’ 22 Paper Collection Skeletons: Declarative Abstractions for Data Collections https://dl.acm.org/doi/10.1145/3567512.3567528
- Intel oneAPI DevSummit 2023 talk Declarative Data Collections for Portable Parallel Performance based on oneAPI https://www.oneapi.io/event-sessions/declarative-data-collections-for-portable-parallel-performance-based-on-oneapi-hpc-2023/
- Github Repo for this project: https://github.com/Tomcruseal/Scale/tree/ContainerAsPara (private, access upon request)
Email: zhibo.li@ed.ac.uk
Call to action
Write a parallel program the data-centric way!
Why it Matters
Programmers are faced with multiple obstacles in developing parallel programs. By introducing Collection Skeletons, a program’s specification is truly decoupled from implementation, reducing the possibilities of mis-specification or over-specification of data collections. Because of the decoupling, Collection Skeletons help shield the application developer from parallel implementation details, either by encapsulating implicit parallelism or through explicit properties that capture the requirements of parallel algorithmic skeletons. Both implicit and explicit parallelism is implemented based on common parallel frameworks, including various components of oneAPI.
Future Plans
- Support more Algorithmic Skeletons.
- Improved concrete data structures decision-making.
- More & reasonable properties for improved data collection declaration.