
oneAPI Poised to Drive AI Proliferation
The oneAPI initiative is set to accelerate the expansion of AI as it optimizes development across heterogenous compute accelerator architectures.
With the increase of supercomputing, computation-intensive algorithms and machine learning based on artificial neural networks, oneAPI is the cross-hardware, platform-agnostic programming solution that is enabling developers to leverage the best architecture for the problem they want to solve without the constraints of vendor lock-in, which is quickening AI adoption across applications and deployments from the edge to the cloud.
Shifting Toward a Standard-Based Programming Model
oneAPI is an open industry, C++ standard-based programming model that empowers developers to develop software for cross-architecture and AI accelerated computation—minus reliance on any specific accelerator architecture. The oneAPI initiative is facilitating a common developer experience that is untethered from hardware specifications, middleware and frameworks. The initiative encourages developer collaboration through open specifications and compatible oneAPI implementations, where all are invited to contribute on the oneAPI spec repository. This unifying programming model is exponentially boosting productivity, innovation and application performance, which are serving to push oneAPI into broadscale, cross-industry ecosystem adoption.
Empowering AI Developers

The exponential growth of data has turned AI from an industry-specific, commercial computing asset to a ubiquitous feature in thousands of applications used to solve problems across virtually every industry. This explosion in growth, however, is placing ever-expanding demands on computer system requirements to deliver higher performance—and it has led to AI acceleration being integrated into the functionality, organization, and implementation of computer systems like CPUs, GPUs and FPGAs.
The oneAPI programming model forms the infrastructure of Intel’s technology chest of AI tools, libraries in deep learning, machine learning and big-data analytics, and framework optimizations like TensorFlow and PyTorch. Open specifications can be applied to Intel’s portfolio of hardware products together with widely used programming languages like Python and C++, among others, which allows for code built on separate frameworks to run efficiently on any hardware accelerator.
Particularly, the oneAPI AI analytics Toolkit gives data scientists and developers access to Python tools and frameworks that allow different compute systems to work in conjunction with each other for efficient AI workflow, from data preparation to training, inference, deployment and scaling. This AI toolkit is empowering developers to speed-up and improve the performance of end-to-end ML/DL pipelines that enable data flow on Intel architectures, including data preparation and ingestion, model training, inference, deployment and monitoring.
The use of oneAPI libraries like Intel oneAPI Deep Neural Network Library (oneDNN)—an open-source, cross-platform performance library for DL applications—have optimized all the biggest and most widely used frameworks like TensorFlow and PyTorch, among others. These Intel software improvements have delivered higher orders of magnitude AI performance gains across deep learning, classical machine learning, and graph analytics without the need to learn new APIs.
Optimizing Intel Deep Learning in TensorFlow and PyTorch
Artificial neural networks have never been easier to learn, build and train, as tech giants like Google and Facebook continue to improve their open-source frameworks—TensorFlow and PyTorch, respectively—for the Python deep learning landscape.
Intel collaborated with Google to streamline its performance on Intel Xeon processor-based platforms using oneDNN to boost compute-intensive operations like convolution, matrix multiplication and batch normalization.
Performance for inference across a range of models was improved by up to 3x. And the oneDNN-enabled TensorFlow for real-time server inference took only 29% to 77% of the time required by the version without oneDNN enablement. For training, performance was improved by up to 2.4x across several established models.
Intel has also collaborated with Facebook to enable PyTorch BF16 CPU optimization using IPEX and oneDNN, which has streamlined both user experience and performance in PyTorch BF16 training and inference. IPEX is a PyTorch open-source extension library powered by oneAPI and is part of the Intel AI Analytics Toolkit. Both IPEX and oneDNN are available as open-source projects.
Two of the most recent advancements resulting from this collaboration include simplifying the usage of BF16 and oneDNN optimization, as well as graph fusion optimization to accelerate BF16 inference performance with oneDNN fusion kernels.
The new IPEX API automates explicit type and layout conversions that users previously had to insert to enable BF16 computation with oneDNN optimizations, which would require significant DL model code changes and disrupt the user experience. This automation facilitates ease-of-use for user-facing API in Python on top of PyTorch.
In addition, Intel and Facebook developers added graph rewrite pass to IPEX based on PyTorch graph intermediate representation, with the optimization pass recognizing oneDNN-supported common fusion patterns and replacing the corresponding sub-graphs with calls to oneDNN fusion kernels. Graph-level model optimization has become essential for users to fully leverage DL workload performance.
A new generation of programming is redefining deep learning. The oneAPI initiative is fast-tracking collaboration on the oneAPI specification and compatible oneAPI implementations across the compute accelerator ecosystem. This acceleration is creating a digital transformation that is driving the adoption of AI and making it part and parcel of humans’ everyday life—all thanks to today’s and tomorrow’s developers who are contributing to deep learning projects powered by oneAPI.
No Vendor Lock-In
One of the most significant benefits of oneAPI is its freedom from vendor lock-in. Programming to any specific CPU, GPU or FPGA restricts the addition of new capabilities or functionality of any software code. oneAPI enables a generalized approach to software that makes it interoperable among various systems, facilitating total abstraction from different hardware accelerators.
And because the oneAPI toolkit is based on C++, millions of developers who participate in the ecosystem are already fluent with these programming languages.
As heterogenous computing systems become the established architecture over the next few years for AI workloads, oneAPI will expand the scope of accelerator vendors. And as the ecosystem develops, optimizations driven by oneAPI will be up streamed into deep learning frameworks like TensorFlow and PyTorch, which will hasten the adoption of this programming interface.
The “X” Approach to Compute Architecture
The “X” stands for any hardware architecture that best fits the need of an application—and today’s applications demand an XPU strategy. Whether for a PC, a car, or a robotic arm, getting a seamless experience from an application requires a mix of hardware architectures, with new languages, libraries, and tools to learn. An XPU strategy offers the widest array of hardware architectures in the industry and a unified programming model to reduce the complexity. With XPU, Intel is helping turn the promise of oneAPI development and adoption across the ecosystem into a reality.
The simplicity and freedom that the oneAPI programming model affords is enabling programmers to quickly port, or develop from scratch, applications that solve real-world problems across industries.
AI workloads like inferencing at the edge are requiring devices with just one circuit element, rather than an integrated circuit, and with embedded compute and acceleration. Additionally, as the internet of things (IoT) gains in popularity, so too is edge computing. An alternative to cloud computing, edge computing processes and stores data closer to end-users. And within core data centers or clouds, high-performance computing will benefit from HPC clusters, which always include various server accelerators on CPUs, GPUs, FPGAs, etc. Therefore, oneAPI is becoming crucial to driving AI computing resources from cloud to the edge.
The oneAPI initiative will eventually become inextricable from AI and intelligent computing, spurring developers to write code to the growing proliferation of accelerators. And as high-performing computing scientists and developers adopt oneAPI and port their code, it will further drive adoption and broaden the ecosystem. How data is moved in and out of AI workflows is becoming critical, and with the rapid increase of edge computing, inferencing will happen at the edge more and more. oneAPI will make intelligent data movement from the edge to core datacenters or clouds exponentially more efficient.
As massive data stores are moved closer to the edge, oneAPI will eventually help to evolve computing by leaps and bounds to a more seamless movement of data with lower latency and higher bandwidth, across devices and compute accelerators. And it will boost performance, which will enable exponential growth of AI.
oneAPI is Today’s Boldest Vision for AI Evolution
The oneAPI industry initiative’s bold vision is to simplify programming by enabling developers to use a unified programming model—whether it’s on a CPU, GPU, FPGA or AI accelerator—that contains a language and a standard library, deep learning tools, a hardware abstraction layer and a software driver layer that can abstract different accelerators, and a set of domain-focused libraries.
Today, the AI ecosystem is at a fertile development stage for developers, researchers and scientists to exploit hardware and software accelerators in close collaboration.
As the world spins toward an IoT reality, startups, small-to-midsize businesses and non-profits in commercial and government industries will be positioning to provide their clients and customers an automated, intelligent multi-device continuum experience from cloud to edge. IoT is leading to an explosion of devices and accelerators, and oneAPI is enabling developers to harness the power of them all—making them pioneers of the ever-expansive digital frontier.
 Get Involved and Review the oneAPI Specification
Get Involved and Review the oneAPI Specification
Learn about the latest oneAPI updates, industry initiative and news. Check out our videos and podcasts. Visit our GitHub repo – review the spec and give feedback or join the conversation happening now on our Discord channel. Then get inspired, network with peers and participate in oneAPI events.
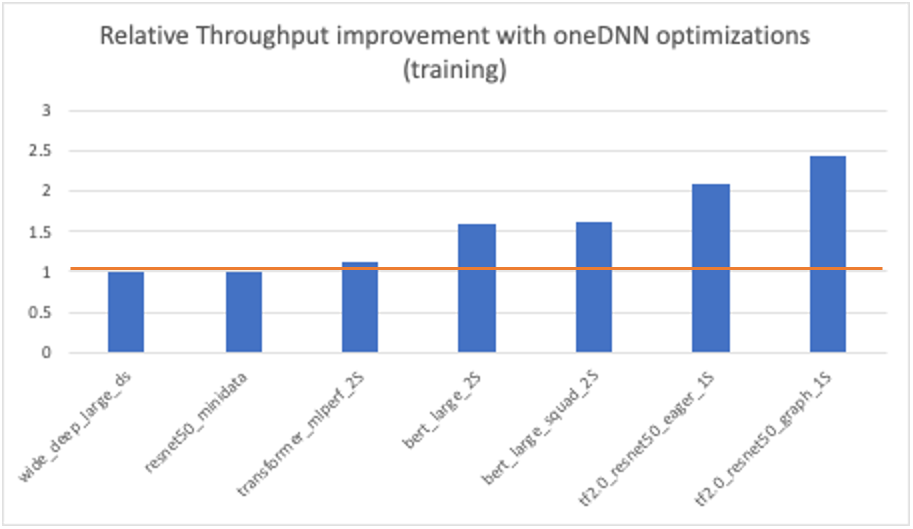
Leverage Intel Deep Learning Optimizations in TensorFlow
TensorFlow is a widely-used deep learning (DL) framework. Intel has been collaborating with Google to optimize its performance on Intel Xeon processor-based platforms using Intel...
Huawei Extends DPC++ with Support for its Ascend AI Chipset
Applying the oneAPI Industry Initiative to Real-World AI Use Cases Wilson Feng, Rasool Maghareh and Amy Wang collaborate on compiler software and research at Huawei’s...