
oneAPI Extended with Graph API to Simplify Integration and Maximize Computation Efficiency
Introduction
Deep Learning frameworks like Tensorflow or Pytorch rely on libraries of optimized primitives to offload computation to AI Hardware. The framework must pattern match its computation graph to identify groups of nodes that can be mapped to a single primitive. This process makes it difficult for a framework to support AI hardware and for a library to implement new primitives that would require new patterns to be implemented in the framework. The oneDNN Graph API makes it possible for a framework to pass an entire graph to a library, and the library maps the graph to primitives or custom generated code. We are pleased to announce that this has been included in the latest oneAPI specification.
 Figure 1. oneAPI extended to include graph API in oneDNN spec
Figure 1. oneAPI extended to include graph API in oneDNN spec
With the introduction of Graph API, the oneDNN spec includes two components: Graph API and Primitives API. Graph API complements the existing Primitives API and does not impact the use of the Primitives API. Graph API focuses on generating optimized code for the DNN computation graph and provides a unified API for AI accelerators. Primitives API focuses on the most performance-critical primitives and a narrow set of fusions.
Existing AI hardware vendors provide two types of performance software for offloading DNN computation graphs, depending on the AI accelerator’s compute capacity and data transfer cost between the AI accelerator and general-purpose computing hardware. For CPU and GPUs, which tightly integrates AI acceleration function unit with a high bandwidth data movement, the vendor library focuses on accelerating a narrow set of DNN operations and DNN computation graph following specific patterns. The second type of graph API assumes a high data transfer cost and offloading the largest-possible DNN computation graph, which is critical to overall performance, and supports a broad set of operations and arbitrary graphs. oneDNN Graph API can be thought of as the best of both worlds – it provides a unified functional interface to allow the implementation to decide the scope of the DNN computation graph to accelerate.
Graph API accepts an arbitrary graph as input and users first construct the maximal DNN computation graph. Users (such as DL frameworks) query the implementation to get a list of Partitions. Graph API partitions the input DNN graph and the partitioning is implementation–dependent. The implementation may decide to put the entire input graph into one partition, or split it into multiple partitions. Each Partition may contain one or multiple ops, which can be compiled and executed as one fused op. When users upgrade their application to use a new version of oneDNN Graph that supports any new optimizations, a new partitioning, is proposed automatically without requiring any changes to users’ code.
Graph API simplifies the integration of a vendor library to high-level deep learning software like AI frameworks and compilers. The integration code is not required to understand the implementation’s optimization capability like specific fusion patterns, and does not have to pattern-match DNN computation graphs and map them to optimized implementation provided by the vendor library. On the other hand, the vendor library can introduce new optimization capabilities without being constrained by the existing integration code. With the simplification of the integration process, Graph API aims to reduce the “time to market” cycle from the new development of vendor library to production deployment of AI models.
Programming model
Graph API introduces graph, logical_tensor, and op to describe a computation graph, and partition to represent the subgraph to be offloaded for acceleration. It also introduces compiled_partition, tensor and reuses oneDNN’s engine and stream. The diagram below shows the relationship between these classes and with the existing oneDNN classes. The arrow indicates the source class used to construct the destination class.
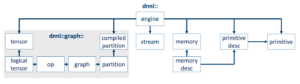 Figure 2. Key classes Graph API introduced to oneDNN
Figure 2. Key classes Graph API introduced to oneDNN
A graph object contains a set of op and logical_tensor. op represents an operation in a computation graph. logical_tensor represents tensor’s metadata, like elements data type, shape, and memory layout. op has kind, attributes, and input and output logical tensors. These classes are introduced to represent a DNN computation graph. The code example below shows how users construct oneDNN Graph graph and partition it to oneDNN Graph partitions.
using namespace dnnl::graph; graph g(engine::kind::cpu); std::vector<int64_t> input_dims {8, 3, 227, 227}; std::vector<int64_t> weight_dims {96, 3, 11, 11}; std::vector<int64_t> dst_dims {8, 96, 55, 55}; logical_tensor conv0_src {0, logical_tensor::data_type::f32, input_dims, logical_tensor::layout_type::strided}; logical_tensor conv0_weight {1, logical_tensor::data_type::f32, weight_dims, logical_tensor::layout_type::strided}; logical_tensor conv0_dst {2, logical_tensor::data_type::f32, dst_dims, logical_tensor::layout_type::strided}; op conv0(0, op::kind::Convolution, “conv0”); conv0.set_attr<std::string>(op::attr::data_format, “NCX”); conv0.set_attr<std::string>(op::attr::weights_format, “OIX”); // set other attributes conv0.add_inputs({conv0_src, conv0_weight}); conv0.add_outputs({conv0_dst}); g.add_op(conv0); logical_tensor relu0_dst {3, logical_tensor::data_type::f32, dst_dims, logical_tensor::layout_type::strided}; op relu0(1, op::kind::ReLU, {conv0_dst}, {relu0_dst}, “relu0”); g.add_op(relu0); // the order of adding ops does not matter. g.finalize(); // retrieve partitions. Each partition may contain one or more ops. vendor library may not support offloading a partition if partition.is_supported() is false. std::vector<partition> partitions = g.get_partitions();
A partition needs to be compiled into a compiled_partition. The engine contains the target device type, which is necessary for the compilation API. The compiled_partition is then executed with input and output tensors. Each tensor contains logical_tensor and the data handle. The stream manages hardware resources at runtime which is passed to the execution API.
engine eng {engine::kind::cpu, 0}; // oneDNN's existing engine API.
compiled_partition cp0 = partitions[0].compile({conv0_src, conv0_weight}, {relu0_dst}, eng);
stream strm {eng}; // oneDNN's existing stream API.
// conv0_src_data, conv0_weight_data, and relu0_dst_data are data retrieved from frameworks or user application.
tensor conv0_src_ts(conv0_src, eng, conv0_src_data.data());
tensor conv0_weight_ts(conv0_weight, eng, conv0_weight_data.data());
tensor relu0_dst_ts(relu0_dst, eng, relu0_dst_data.data());
cp0.execute(strm, {conv0_src_ts, conv0_weight_ts}, {relu0_dst_ts});
Integration with deep learning graph compiler
Graph API is designed to accelerate AI frameworks on AI accelerators with low overhead so that an implementation could be tightly integrated as a built-in module of the AI framework that uses it. AI frameworks usually contains a deep learning graph compiler, which develops its own DNN computation graph intermediate representation (IR) to describe the input DNN model. It optimizes the DNN graph IR, lowers some regions of the DNN graph to machine code with a low-level tensor compiler for custom code generation, implements some regions using vendor library as well as custom primitives. It then runs the DNN graph IR by iterating the graph and calls each region’s corresponding implementation. Graph API is integrated into graph optimization, lowering, and execution.
First, the deep learning graph compiler needs to add a dedicated optimization pass which establishes the mapping between a DNN computation subgraph and a oneDNN Graph partition. The optimization pass iterates the DNN computation graph, converts DNN op together with its input and output as oneDNN Graph op and associated logical tensors, and adds that oneDNN Graph op to oneDNN Graph graph. Then it calls partition API to get partitions, locates their corresponding DNN compute subgraph, and replaces them with a custom op associated with the partition.
At graph lowering time, when the deep learning graph compiler lowers the DNN computation subgraph, the integration code lowers custom ops to corresponding function calls to a oneDNN Graph compiled partition. The integration code first retrieves the partition associated with the custom op, compiles the partition using Graph API, and records the compiled partition with the lowered form of the DNN computation subgraph.
At execution time, the implementation of custom op interacts with the AI framework runtime to retrieve the input and output of the custom op, converts them to oneDNN Graph tensors, and passes them as parameters to the oneDNN Graph compiled partition for execution. After the execution of the compiled partition completes, the integration code receives the result and passes it to framework runtime as custom op’s output. No extra data buffer copies are required during the runtime so the compiled partition can be mixed with the other kernel implementation or code generated from low-level tensor compiler to support a whole DNN computation graph.
Users that don’t use an AI framework and directly program for AI hardware can use the Graph API to construct a DNN computation graph and offload it to AI hardware.
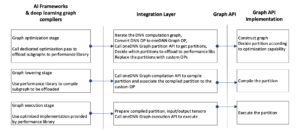 Figure 3. Overview of framework integration with the oneDNN Graph API
Figure 3. Overview of framework integration with the oneDNN Graph API
Implementation and adoption
The oneDNN library implements the Graph API specification. With multiple preview releases, the API is being leveraged by various frameworks. Along the journey, development of the Graph API received valuable feedback from AI frameworks and the oneAPI community and matured with increasing data types and operation scope. Today, the Graph API supports both inference and training on CPUs and GPUs, and all the data types currently adopted by in-production deep learning frameworks.
Below is a list of framework adoption in the order of release date of its first adoption.
- graph-v0.4.2 was first adopted by Intel® Extension for Pytorch v1.11 for CPU release for CPU inference
- graph-v0.5 was integrated into stock PyTorch and released in PyTorch v1.12 as a prototype feature for CPU inference
- graph-v0.7 was adopted by the initial version of Intel® Extension for Tensorflow integrated for both CPUs and GPUs, and inference and training
Looking forward
The deep learning field is changing rapidly, which poses unique challenges for integrating support for new hardware into frameworks. Without a clearly defined interface, software development efforts to enable new AI hardware could be fragmented and could potentially be unable to benefit from reuse. oneAPI’s focus is to provide a standard interface and help the industry converge more easily to modular software development.
With oneAPI being adopted by multiple deep learning frameworks driven by high performance implementations on Intel AI hardware, the oneAPI interface-based framework integration could be reused by any third-party API hardware vendors, significantly reducing their low-level software development efforts – including low-level vendor library and framework integration.
 Figure 4. The vision of reusing framework integration with oneDNN Graph API for future AI hardware
Figure 4. The vision of reusing framework integration with oneDNN Graph API for future AI hardware
Get involved and join the oneAPI Community Forum
 Learn about the latest oneAPI updates, industry initiatives and news. Check out our videos and podcasts. Visit our GitHub repo to review the spec and give feedback. Or join the conversation happening now on our Discord channel. Then get inspired, network with peers and participate in oneAPI events.
Learn about the latest oneAPI updates, industry initiatives and news. Check out our videos and podcasts. Visit our GitHub repo to review the spec and give feedback. Or join the conversation happening now on our Discord channel. Then get inspired, network with peers and participate in oneAPI events.

Accelerate PyTorch with IPEX and oneDNN using Intel BF16 Technology
Introduction Intel and Facebook previously collaborated to enable BF16, a first-class data type in PyTorch. It supports basic math and tensor operations and adds CPU...
Accelerating TensorFlow with oneDNN
TensorFlow defaults to Intel oneDNN AI optimizations
Following Google and Intel’s partnership, the open-source TensorFlow has announced that their machine learning library is being updated. Intel’s open-source oneAPI Deep Neural Network Library...