
Bringing Nvidia® and AMD support to oneAPI
Developers can write SYCL™ code and use oneAPI to target Nvidia* and AMD* GPUs with free binary plugins

Today is a milestone for me as Codeplay® officially releases plug-ins for oneAPI on Nvidia and AMD GPUs along with technical support, see the announcement. I have been working on this project from the beginning and it’s exciting for our team to be able to make this available to the broader developer community. This release provides plugins for the Intel® DPC++/C++ Compiler using the oneAPI Toolkits to enable Nvidia and AMD GPU platform targets. Although support for Nvidia and AMD GPUs has been available in the DPC++ open-source repository for a while now, this is the first official binary release. Together with this release, Codeplay is providing a commercial “Priority Support” package for customers who want quick answers to technical problems and general support for their oneAPI deployment on Nvidia platforms directly with our team.
If you want to jump straight into using the new release visit our “Get Started” guide for Nvidia GPUs or “Get Started” guide for AMD GPUs. You can find out what features are and aren’t yet supported for the plugins on the “Features” pages.
What we are releasing are plugin components that complement the Intel® oneAPI Toolkits. The Intel oneAPI Toolkits provide the DPC++/C++ Compiler with the OpenCL and Level Zero plugins by default, and the Codeplay plugins introduce support for the Nvidia and AMD GPU platforms respectively. The Codeplay plugins require the Intel oneAPI Base Toolkit to be installed, they cannot be used on their own.
The Codeplay plugins will be released with the same cadence as the Intel oneAPI Toolkit releases; this first one being 2023.0, with additional minor releases which will match the latest CUDA and ROCm SDK releases, ensuring that the plugins work with the latest platform drivers.
In the 2023.0 release, oneAPI for Nvidia GPUs has most SYCL 2020 features implemented.
The oneAPI for Nvidia GPUs plugin primarily supports Nvidia A100 GPUs, with at least CUDA SDK 11.7 and the recommended Nvidia driver. However, any GPU with at least compute capability sm_50 should work.
oneAPI for AMD GPUs is still in beta stage, but it does implement more than 50% of the SYCL 2020 features.
The oneAPI for AMD GPUs plugin is primarily supported on AMD W6800 GPUs (gfx1030) with ROCm 4.5.2. We do however also test regularly using AMD MI50 (gfx906), MI100 (gfx908) and Radeon RX 6700 XT (gfx1031) GPUs.
We’re interested to hear from the community who are using the plugins with a range of GPUs.
Supported Features
All major SYCL 2020 features are supported on the Nvidia GPUs plugin, including the various levels of Unified Shared Memory (USM), subgroup algorithms, atomics and reduction operations. Some advanced SYCL extensions are also working and mapped efficiently to CUDA, for example Nvidia Tensor Cores can be programmed using the “joint_matrix” extension from Intel, using the same performance portable code as in similar Intel hardware features, such as Intel® Advanced Matrix Extensions (Intel® AMX).
SYCL applications using our plugins on Nvidia or AMD GPUs are using the same execution path as any other CUDA and HIP applications. Traditional Nvidia tools, such as profilers (nsys, ncu) or debuggers (cuda-gdb), can be used with SYCL applications using Data Parallel C++ (DPC++). Advanced users can extract the generated PTX from the compiler pipeline to identify potential low-level optimizations, and the PTX is converted to SASS using native CUDA tooling.
Backend interoperability is an important aspect of the SYCL 2020 specification and fully supported by oneAPI for Nvidia GPUs. Users can retrieve native CUDA objects from almost any SYCL object, for example, CUDA streams from SYCL queues or CUDA events from SYCL events. It is possible to use native CUDA libraries, such as cuBLAS or cuDNN with SYCL applications using the interoperability mode.
SYCL enables features that are not available on AMD or HIP. One example is the ability to asynchronously execute arbitrary C++ code on the host following the same dependency scheduling as the devices. This is done using SYCL host tasks.
How is this all possible
oneAPI for Nvidia GPUs relies on the infrastructure that Codeplay has built for the past three years in the DPC++ open source repository. Codeplay has been taking advantage of the SYCL 2020 capability of targeting multiple different backends to extend DPC++ with support for Nvidia GPUs via CUDA and AMD GPUs via HIP. Codeplay also proposed a CUDA backend specification to the Khronos SYCL working group to enable other vendors to provide their own SYCL implementations for CUDA.
It has been possible to compile using DPC++ for Nvidia GPUs for more than a year on Lawrence Berkeley National Laboratory, Oak Ridge National Laboratory, and Argonne National Laboratory clusters. Codeplay has been working in collaboration with these organizations so that researchers can prepare their codes to run on the Aurora, Frontier, Polaris and Perlmutter supercomputers. This is making it easier to move code across hardware platforms from multiple vendors.
The implementation we have contributed to DPC++ of Nvidia and AMD GPU targets has two main components. One part includes several clang++ compiler driver patches, and the other implements the runtime plugin itself. The compiler changes were integrated into the code that is built to produce the Intel oneAPI Base Toolkit in order to simplify distribution. The plugin is built separately and only available in oneAPI for Nvidia GPUs and oneAPI for AMD GPUs, downloadable from the Codeplay developer website. Note the standalone oneAPI Toolkits will allow compilation of SYCL applications targeting Nvidia and AMD architectures, by that I mean the target flags will be accepted by the compiler, however without the runtime plugin components they will not execute.
The compiler driver patches enable the DPC++ frontend to build for Nvidia GPUs by identifying the target triple, and then triggering actions to build the device image using the existing CUDA compiler support from the LLVM project.
The DPC++ frontend pushes the SYCL code down several passes and then calls the PTX backend from LLVM to generate the PTX for the kernels in the SYCL application. Codeplay engineers are actively contributing and improving support for new PTX ISA features, such as tensor cores, to ensure performance of the code generated with the LLVM PTX backend is on comparable with the native NVCC compiler. By adopting the upstream LLVM PTX, the DPC++ Nvidia plugin can benefit from a large community of developers already working with Nvidia GPUs. The generated PTX ISA is usually comparable with the native NVCC compiler when using the same optimization flags. Note that NVCC enables several default flags silently that must be spelled out on the DPC++ CUDA backend, our documentation shows how to enable the right ones.
The other components are the runtime plugins, which enable the SYCL runtime to call native APIs on Nvidia and AMD platforms (CUDA Driver and HIP respectively). The runtime plugins are dynamic libraries that are called from the SYCL runtime when available. The DPC++ compiler automatically links against the SYCL runtime from the oneAPI distribution, and then if the Nvidia and/or AMD plugins are available, they can be selected at runtime for execution. Using the SYCL device selection in the application allows it to specifically select an Nvidia (or AMD device), as shown in Figure 1.
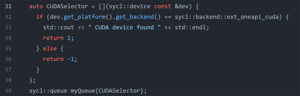 Figure 1: Example of a CUDA device selector that prints a message when a CUDA device has been found. If there is no CUDA device, the SYCL queue will throw an error.
Figure 1: Example of a CUDA device selector that prints a message when a CUDA device has been found. If there is no CUDA device, the SYCL queue will throw an error.
Future Plans
During 2023 we will add more features to continue to support the latest AMD and Nvidia GPUs and SDK releases and extend the number of platforms tested and supported. We also welcome contributions from the community through the open source project.
We will broaden hardware support of the oneAPI specification components such as the oneAPI Math Kernel Library (oneMKL) and oneAPI Deep Neural Network Library (oneDNN). Official releases will be prepared for these libraries using cuBLAS, cuDNN, hipBLAS and hipDNN support, ensuring that they are properly supported and “Priority Support” can address critical issues.
Further in the future, Codeplay hopes to add more multivendor hardware support to other oneAPI libraries, like oneAPI Data Parallel C++ Library (oneDPL), and help to make the migration to SYCL as seamless as possible for developers with Nvidia and AMD hardware.
Get Started
If you want to use the C++ SYCL compiler for Nvidia or AMD platforms, you can still get the source code and build it yourself from the Intel LLVM repository, following the Getting Started guide. That is the best way to get the cutting-edge features. You can interact with the open source community there, asking questions or raising issues. Development of all Nvidia and AMD support happens in the open source project first, and we are deeply committed to fostering an open ecosystem to develop oneAPI support for multiple platforms with a strong community behind it.
Alternatively you can download the plugins from our developer website and request Priority Support from Codeplay by contacting us.
If you have any technical questions you can raise them on our community forum .
Notices and Disclaimers
* Other names and brands may be claimed as the property of others.
1 Performance varies by use, configuration and other factors.
Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. See backup for configuration details. No product or component can be absolutely secure.
Your costs and results may vary.
Intel technologies may require enabled hardware, software or service activation.
© Codeplay Software Ltd. Intel, the Intel logo, Codeplay and Codeplay logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others. SYCL is a registered trademark of the Khronos Group, Inc.
Bringing SYCL to pre-exascale supercomputing with DPC++ for CUDA
Codeplay’s Contribution Brings NVIDIA Support For SYCL Developers
Codeplay has made significant contributions to enabling an open standard, cross-architecture interface for developers as part of the oneAPI industry initiative.
Oak Ridge National Laboratory Establishes oneAPI Center for Excellence
Dr. Zheming Jin, a research scientist at Oak Ridge National Laboratory (ORNL), is leading ORNL’s effort to study how various approaches to parallel programming, including...