
Dive achieves 1.5X speedup in Vectorization with latest Intel CPU and oneAPI Software – founded on the unified, open, standards-based oneAPI programming model.
Introduction
Machine component simulation has become an indispensable part of product development. While other industries shifted to the cloud years ago, research and development (R&D) departments of mechanical engineering companies remain behind. Recently, however, cloud-native engineering solutions have been enjoying a boom, and in the high-performance computing (HPC) sector in particular, many workloads are being shifted to the cloud.
For providers of cloud-native solutions, the advantage is obvious: They can efficiently allocate their resources to optimize the software for specific hardware types available in the cloud and do not have to provide their software for various operating systems and hardware types as do their on-premise counterparts.
Dive Simulation Platform
In collaboration with Intel, Dive has optimized its cloud environment to increase cost efficiency for its customers, reduce the time-to-result of simulations and ultimately increase the user experience.
Dive’s cloud-native simulation platform provides access to Computational Fluid Dynamics (CFD) solvers. The applied Lagrangiansimulation method Smoothed Particle Hydrodynamics (SPH) is superior to classical grid methods in various use cases, enabling engineers to simulate and evaluate even the most complex processes such as heat transfer in e-engines or loss assessments in high-speed gearboxes.
 Figure 1: Use Cases of Dive’s particle-based simulation technology
Figure 1: Use Cases of Dive’s particle-based simulation technology
Dive’s cloud-native simulation platform is based on a Software-as-a-Service (SaaS) model, which allows customers to only pay for the cloud hardware resources they effectively need for the simulation. Optimizing simulation performance and therefore reducing the runtime pays off twice for the customer: First, the reduced runtime saves costs on cloud hardware, and second, it simply saves time.
Challenge: Hardware Bottlenecks
The Bottlenecks of Numerical Algorithms
A limited performance of an algorithm is always linked to either computation or memory. In the first case, the CPU is limited by its own speed, i.e., the application is compute-bound.
In the second case, the CPU is waiting for memory transfers being completed to execute further instructions. This can either be caused by a limited memory bandwidth, i.e. bandwidth-bound, or by the CPU pipeline not being fully utilized due to single reoccurring memory instructions which block further execution due to the latency of the memory subsystem, i.e. latency-bound.
Identifying how an algorithm is bounded by the hardware reduces the number of possible optimizations and helps to point out the most promising.
Dive’s cloud-native simulation platform is based on a Software-as-a-Service (SaaS) model, which allows customers to only pay for the cloud hardware resources they effectively need for the simulation. Optimizing simulation performance and therefore reducing the runtime pays off twice for the customer: First, the reduced runtime saves costs on cloud hardware, and second, it simply saves time.
Challenge: Hardware Bottlenecks
The Bottlenecks of Numerical Algorithms
A limited performance of an algorithm is always linked to either computation or memory. In the first case, the CPU is limited by its own speed, i.e., the application is compute-bound.
In the second case, the CPU is waiting for memory transfers being completed to execute further instructions. This can either be caused by a limited memory bandwidth, i.e. bandwidth-bound, or by the CPU pipeline not being fully utilized due to single reoccurring memory instructions which block further execution due to the latency of the memory subsystem, i.e. latency-bound.
Identifying how an algorithm is bounded by the hardware reduces the number of possible optimizations and helps to point out the most promising.
 Figure 2: Major hardware bottlenecks during program execution
Figure 2: Major hardware bottlenecks during program execution
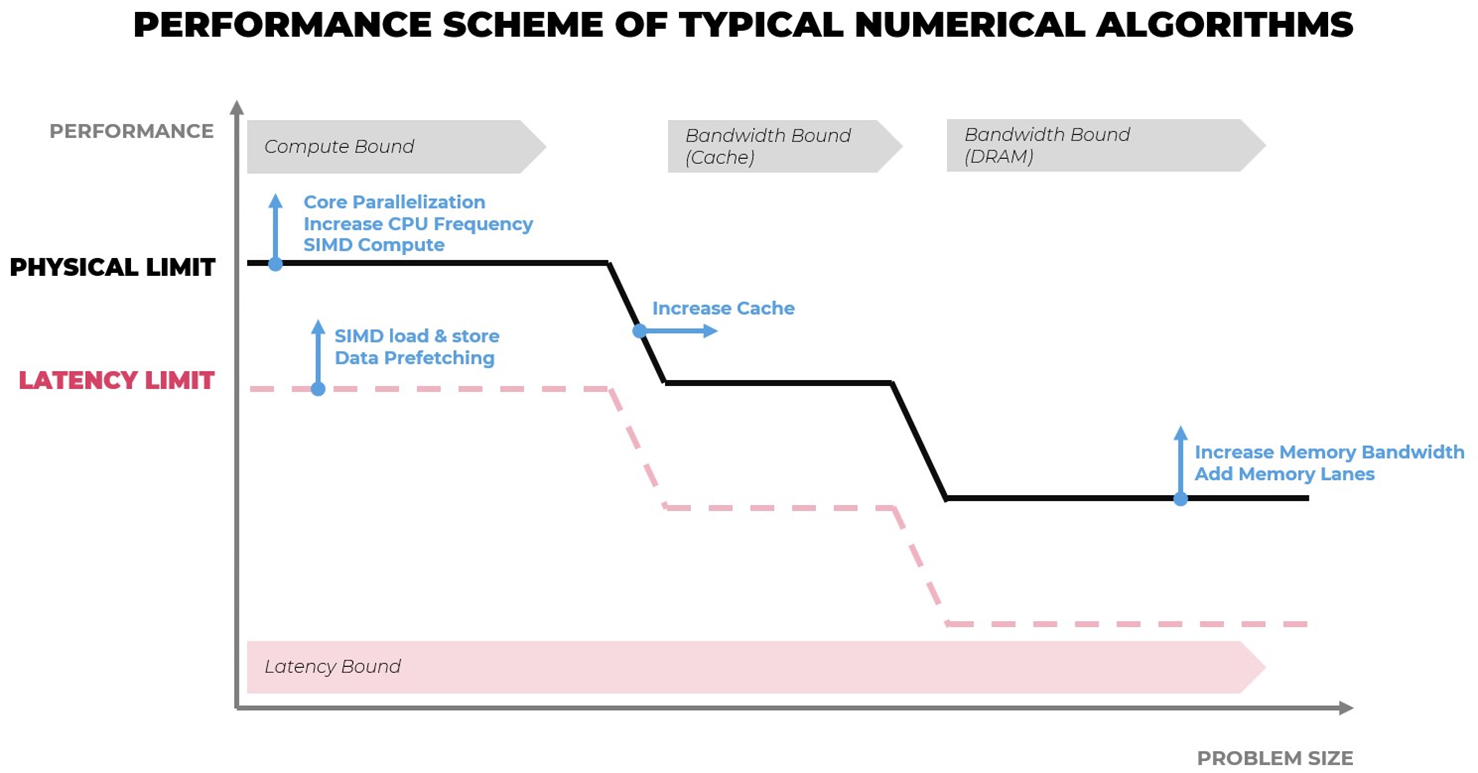 Figure 3: Performance scheme of typical numerical algorithms. In blue, potential solutions which increase the performance are mentioned.
Figure 3: Performance scheme of typical numerical algorithms. In blue, potential solutions which increase the performance are mentioned.
CPU Vectorization as a Potential Source for Performance Gains
Regarding modern CPU architectures, Single Instruction Multiple Data (SIMD) describes extensions that allow processing of multiple values in a single instruction. Several standards were published improving their successors, e.g., SSE (2x double precision values), AVX (4x) and AVX-512 (8x). Most current x86 architectures support at least AVX; as of now only Intel processors support AVX-512.
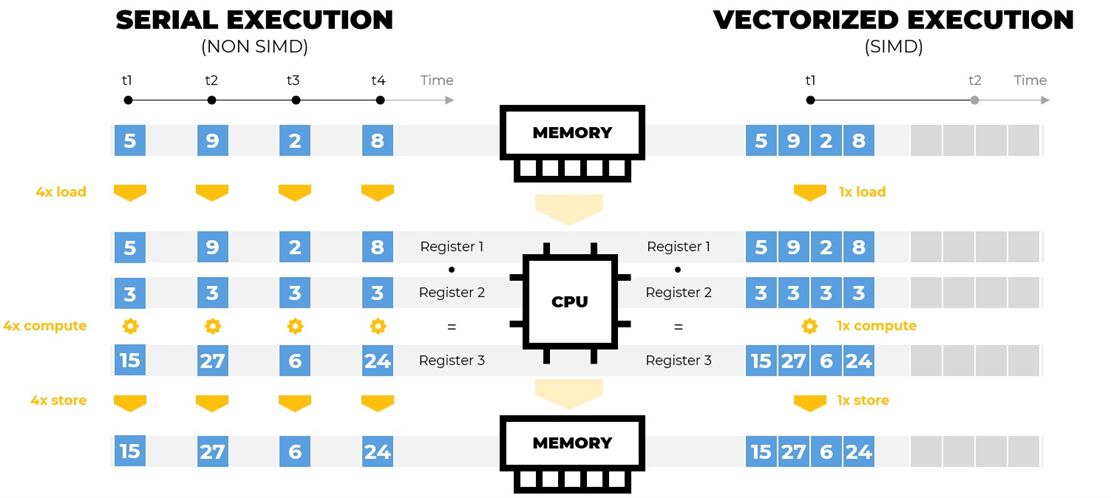 Figure 4: Visualization of instruction and time improvement due to a vectorized execution on AVX. Four values are multiplied by the number 3. These values must be loaded from the memory into the CPU, calculated, and the result must be stored. In theory, the vectorized execution is 4x faster.
Figure 4: Visualization of instruction and time improvement due to a vectorized execution on AVX. Four values are multiplied by the number 3. These values must be loaded from the memory into the CPU, calculated, and the result must be stored. In theory, the vectorized execution is 4x faster.
With SIMD, it is possible to merge multiple arithmetic or memory instructions to one. Thus, it reduces the number of instructions necessary to complete a task. This benefits mostly compute-bound algorithms, but in the case of non-sequential load or store operations, it can also improve latency-bound computations due to the additional parallelism in memory operations.
Theoretically, the achievable speed increase corresponds to the number of values that can be processed in a SIMD instruction, but in most cases it is significantly lower due to higher costs of the instructions, reduced clock frequency, higher utilization of cache lines, and reaching the bandwidth limit of the main memory.
Dive’s need for an explicit SIMD implementation
Dive’s fluid solver is written in C++ and exploits CPU-based parallelism using OpenMP*. Due to the Lagrangian nature of the underlying algorithm, the main compute kernels are based on non-sequential load and store operations, which prevent the compiler from automatically vectorizing the computations. Thus, intrinsic functions1 are used to force the compiler to use SIMD instructions.
Using a C++ abstraction layer for vectorized computations
Using intrinsic SIMD functions comes with higher maintenance costs. For each new instruction set whole parts of code need to be changed, code needs to be duplicated when older and newer versions need to be provided at the same time, and code readability decreases drastically.
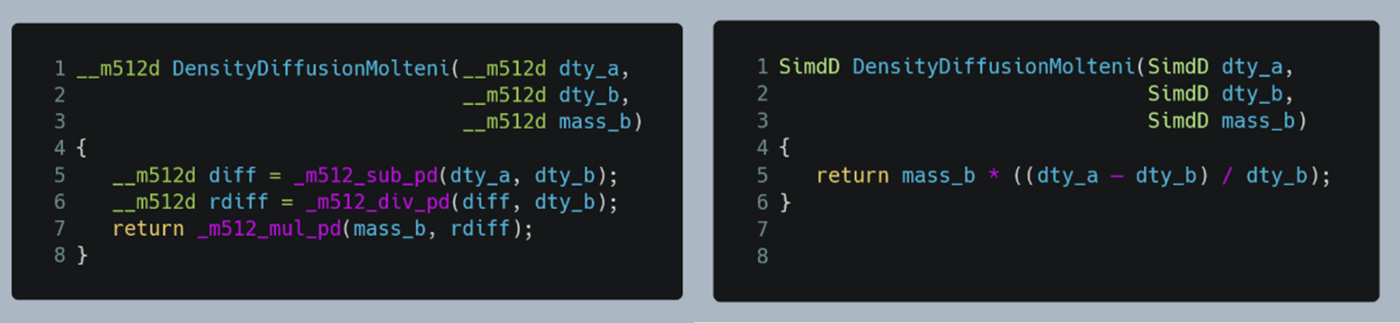 Figure 5: Two explicit, vectorized implementations of a simplified density-diffusion operator2. Left: explicit intrinsic function usage. Right: abstraction layer usage through the structure “SimdD”.
Figure 5: Two explicit, vectorized implementations of a simplified density-diffusion operator2. Left: explicit intrinsic function usage. Right: abstraction layer usage through the structure “SimdD”.
To overcome these issues, an abstraction layer is introduced through which the specific SIMD implementation can be hidden. Thus, the compute kernels are implemented based on the abstraction. The support of a future SIMD instruction set can be added by providing an additional implementation for the abstraction layer. Which specific SIMD version is used can be defined during compilation. Readability is improved through providing an additional operator overloading. A reference implementation for a SIMD abstraction layer was already discussed by the C++ Standard Committee3.
Outcome: 1.5 Speedup through Vectorization in an Industry Application using Intel® VTune™ Profiler
By introducing an explicit AVX-512 vectorization, the performance of the solver was increased by a factor of 1.5.
For benchmarking, a gearbox similar in complexity and size to a typical customer case was used. To gain insights into the behavior of the application, Intel® VTuneTM Profiler was used before the improvement and in advance. Especially valuable are the performance metrics about vectorization, bandwidth, and memory bottlenecks. These metrices are all included in the VTune Profiler HPC performance metric.

Figure 6: Rear axle test rig gearbox of a sedan car. 5M particles, 0.25M boundary triangles4.
Upwards: From latency-bound to memory-bound
The Intel VTune Profiler metrics revealed two interesting phenomena:
First, the CPU stalled 25% of the time on memory requests—11% due to cache and 14% due to DRAM for the auto-vectorized code.
With the explicit vectorization, the percent of memory stall time increased to 43% equally distributed over cache- and DRAM-bound.
Despite the unfavorable access patterns in the code, the bandwidth utilization was further increased from 40 GB/s (auto vectorization) to 55 GB/s (explicit vectorization). These numbers suggest that the introduction of explicit vectorization brought the previously compute- and latency-bound code closer to the physical limit, namely compute and bandwidth.
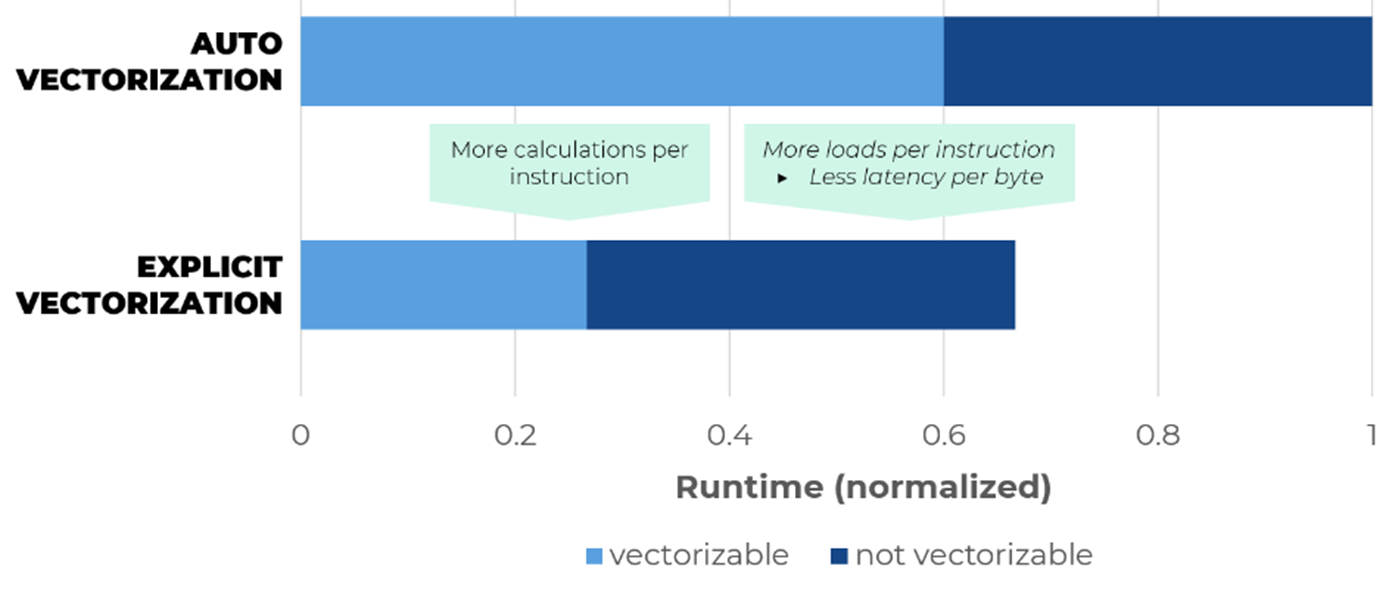 Figure 7: Runtime improvement through AVX-512 on dual socket Intel® Xeon® Scalable Gold processor 6342 using GCC 11.2.
Figure 7: Runtime improvement through AVX-512 on dual socket Intel® Xeon® Scalable Gold processor 6342 using GCC 11.2.
Second, the portion of SIMD calculations increased from 7% in the auto-vectorized code to 60% in the explicit-vectorized code using the SIMD abstraction layer. This insight was crucial for putting the theoretical hardware speedup of 8x of AVX-512 in perspective: using Amdahl’s Law with 60% of SIMD parallelizable instructions, we get a theoretical maximum speedup of 2x.
The achieved speedup of 1.5x measured under real operating conditions is very close to an optimal result and shows the impact of vectorization also for particle-based codes. It was possible to push the performance closer to the hardware bandwidth limit, resulting in a much more efficient use of the Intel chips.
What’s Next?
Thanks to Intel VTune Profiler and access to the Intel® Developer Cloud, Dive gained deeper insights into the runtime behavior of its algorithms on the latest Intel CPUs. An initial explicit vectorization on AVX-512 shows promising potential for improving the runtime of the simulation models. Through further insights from Intel’s hardware and software stack, Dive has already identified NUMA node balancing as a next step for optimization.
We encourage you to check out Intel’s other oneAPI tools and learn about the unified, open, standards-based oneAPI programming modelthat forms the foundation of Intel’s Software Developer Portfolio.
Acknowledgement
This project was implemented within the scope of Intel® oneAPI for Startups, a free, virtual, startup accelerator program designed to help early-stage tech startups on their path to innovation and growth. The primary mission is to inspire and empower startups with Intel’s leadership in technology. Dive Solutions joined the program in April 2022.
Intel Developer Cloud is a cloud-native, free service platform for software developers and eco-system partners, providing early and efficient access to Intel® technologies.
Dive would like to thank Ryan Metz and Rahul Unnikrishnan Nair from Intel for their relentless support during the program.